
数据预处理的方法有哪些
说到数据预处理,咱们可得聊聊几种常见的神奇方法,绝对让你大开眼界!
-
粗糙集(Rough Set)方法:这个方法基于数学工具,用来处理那些模糊不清、不太确定的知识。它可是KDD领域里大受欢迎的利器!为什么呢?因为它能帮你有效地精简数据维度,噢,真的超实用!
-
基于概念树的数据浓缩:在数据库里,很多属性其实都能归类管理。通过不同抽象程度的属性值,构成一个层次分明的概念树。这树是不是听起来很酷?这可不是随便说说,领域的专家们都得给你支招儿,这层次结构帮你从一般到特殊,逐层理清数据,让数据变得更清楚明白。
-
信息论方法:这方法嘛,咱这篇文章不展开了,但它也是玩转数据降维和噪声处理的高手哟!
总之,掌握这些方法,你的数据预处理工作就像开了外挂一样,效果杠杠滴!
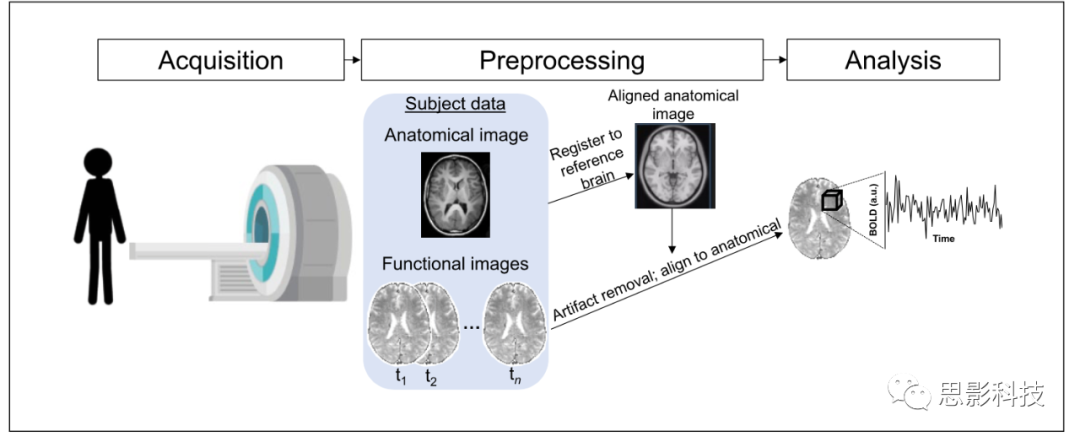
数据采集和预处理的步骤怎么高效完成
嘿,别以为只会用方法就够了,实际操作步骤咱也得清楚才行!来,听我给你理理头:
-
处理不同数据源兼容性:你知道吗?数据采集过程,会碰到各种各样的数据源,有同样结构的数据库,也有五花八门的文件系统、服务接口。预处理阶段的头等大事就是让这些数据“说同一个语言”,搞定它们的兼容性问题,才不会出错,关键!
-
清洗数据:哎呀,这步多重要!数据里肯定会有噪声数据、缺失值、有冲突的地方。咱要花心思把它们一一清理干净,保证数据的纯净度,这样后续的分析和处理才能靠谱,赞不赞?
-
确保数据真实性与有效性:这点别忘了,通过预处理剔除虚假数据是必须滴!只有真实有效的数据,咱们的结果才有意义,不然就是大海捞针。
-
使用预处理语句提高效率:比如在OLTP场景,超级建议你用Prepared Statements(预处理语句)来代替普通文本执行。这样SQL语句模板化,重复利用预处理语句就能避开重复解析的帽子!关键配置像
useServerPrepStmts = true和cachePrepStmts = true,都是必不可少的好伙伴,听我说,这能让数据库的执行效率嗖嗖上涨! -
预编译操作熟练掌握:比如用数据库驱动完成预编译,或者用PreparedStatement对象来更新、查询数据,这些都能帮你的开发体验和运行效率提升几个档次。
-
处理特殊数据格式及操作:像SPSS Modeler处理MR数据时,你得特别注意关键字段的准确性和一致性,不然数据就像打了马赛克一样模糊。输出节点用来转成CSV或者直接屏幕显示,各种步骤都得细心操作才行。
说白了,这套操作流程是打通你整个数据处理链的秘密武器,跟你说,掌握了妥妥的!

相关问题解答
-
数据预处理到底有哪些实用方法啊?
说真的,数据预处理主要有粗糙集来处理不确定性,概念树帮你归类、精简,还有信息论带来妙招。这些方法都是给你专门用来“瘦身”数据的,就像帮你去掉那些不重要的噪音,效果杠杠滴!听我一句,学会这些你就赢了! -
为什么数据清洗这么重要,不能跳过吗?
哈哈,这就对了,清洗数据超关键啊!要不然数据里那些脏东西(噪声、缺失、冲突)会把你的分析搞得乱七八糟,最后得到的结果简直不靠谱!清洗就是给数据洗个澡,清清爽爽,搞定一切麻烦。 -
使用预处理语句(Prepared Statements)有什么特别牛的地方?
啊,这个真心推荐!预处理语句能把SQL语句模板化,反复利用,避免数据库一次次重新解析,节省超多时间和资源。配置如useServerPrepStmts=true,直接让服务端处理预编译,性能up up up!这玩法特别适合OLTP场景,便捷又高效。 -
如何确保数据的真实性和有效性看似简单却扎心?
嘿,这活确实不简单。你得细心检查数据有没有假的、错误的,甄别出无效记录,放心,这不是瞎忙活,是保证你的分析结果靠谱的保障。只要做好这步,后面无论怎么瞎折腾,数据都会给你撑场面,稳稳的!







新增评论