
MySQL模糊查询为什么LIKE和CONCAT组合会导致索引失效
说到MySQL里的模糊查询,大家肯定第一反应就是用LIKE配合百分号%,然而这招用多了,尤其是像LIKE加上CONCAT这种组合方式,索引就很容易掉链子,变得没啥用处了。其实这是因为数据库在用这招子的时候,根本没法走索引,只能整张表一条条扫过去,哇塞,性能一下子掉得不要不要的。
别担心,这儿有招:
1. 拆分查询。就是说把一个查询拆成两段,先按简单条件查,再用程序处理结果。这样就避免了数据库直接用LIKE和CONCAT混搭,性能蹭蹭往上涨。
2. 使用全文索引。这是MySQL官方给力的功能,从5.6版本开始InnoDB存储引擎支持全文检索,简直是为模糊查量身打造。它利用倒排索引,能超快锁定关键词,远远比LIKE更牛哦。
3. 效率对比上,全文索引不仅速度更快,还能支持多种搜索模式,比如自然语言搜索、布尔搜索,真是超级灵活。
拜托,以后别光靠LIKE+%,换招试试这些高效方法,绝对有惊喜!
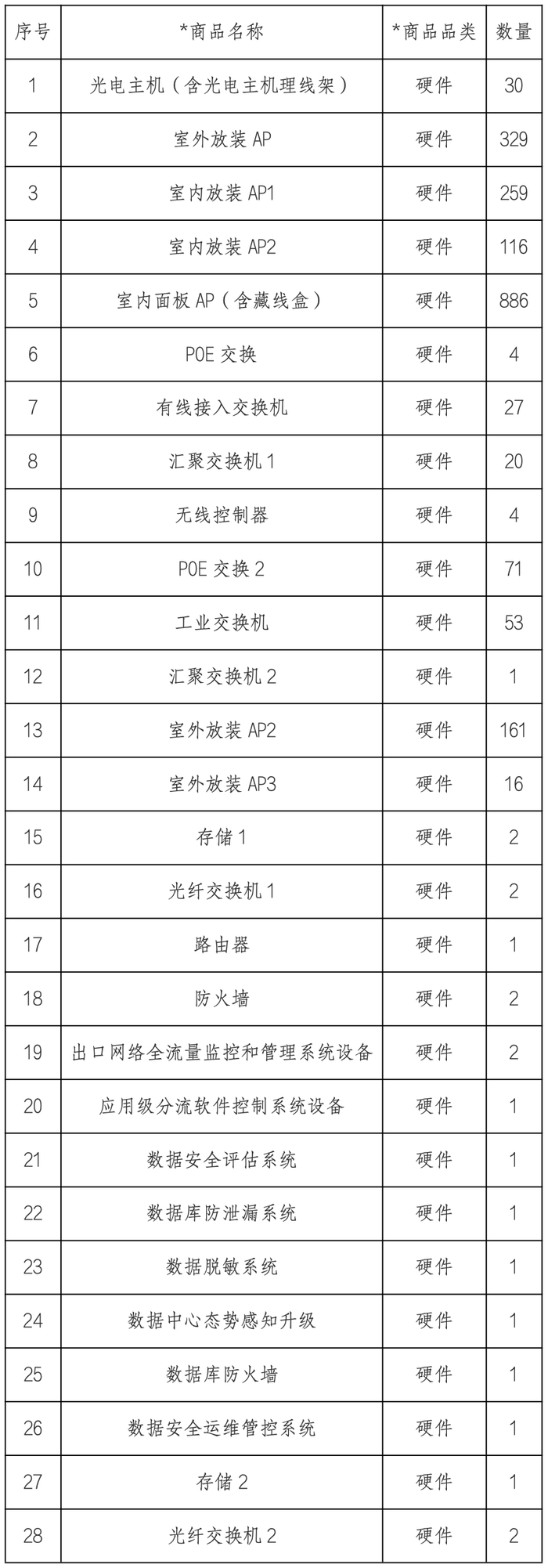
MySQL模糊查询除了LIKE还能用什么方法提高效率
别老用LIKE搞得头大啊,咱们还有其他骚操作呢!先来说几个直接用得着的小技巧:
1. 哈希索引法。如果你的字段不长且内容比较确定,可以用crc32()函数把字段转换成数字,再用=来精准匹配,效率大大提升。你看,扩展学习一下,大部分时候都能用上!
2. 字符串前缀匹配。如果只想查字符串左头或者右头,那用left()或right()函数就倍儿好用,比用全模糊LIKE效率高多啦。
3. 多字段模糊查询优化。咱们经常要对好几个字段做模糊查,对吧?比如where a like '%xx%' or b like '%xx%' or c like '%xx%'这种写法很糟糕,性能爆炸!其实可以用instr(nvl(a, '')||nvl(b,'')||nvl(c,''), 'xx') > 0来替代,这样MySQL能更优雅地处理,让查询更加省时省力。
4. 数字型字段的优势。记得尽量使用数字型字段做查询和连接,逃离那坑爹的字符串比较,爽快多了。
5. 避免全模糊扫描和索引失效。全模糊LIKE(比如%xxx%)是最难优化的,真有必要的话,考虑用专业的搜索引擎解决,更省心。
终极目标嘛就是啥呢?少用LIKE,正确地用索引,别让数据库变成“扫雷现场”!这样查询快,服务器压力小,整个系统都嗨皮了。

相关问题解答
-
MySQL里为什么用LIKE和CONCAT组合会让索引失效?
哎呀,这问题问得太好了!你想啊,当你用LIKE配合CONCAT时,MySQL得先把这些字符串“粘”在一起才能查,那一刻它根本没法利用已有索引的结构,只能从头往尾扫,哇!性能直接翻车。当然,如果拆分查询,过程就会轻松多了,数据库就能乖乖走索引啦! -
除了LIKE,还有啥办法做模糊查询吗?
完全有啊!哥们儿,你听我说,像哈希索引嘛,把字符串用crc32转换下,用等号精准匹配,效率杠杠的。还有全文索引,专门为这事设计,速度飞起!而且多字段模糊查也可以用instr()函数拼接来搞,省事又快,简直是懒人的福音。 -
全文索引真有那么神奇吗?
得嘞!全文索引用倒排索引的方法,能快速定位每个关键词出现的位置,就跟在大海捞针一样,但比你想象的快多了。它还能支持各种搜索方式,像自然语言和布尔搜索,完全满足你各种花式查询的需要。比起传统的LIKE,简直是性能和体验的双丰收! -
怎么避免查询时数据库进行全表扫描?
嘿!全表扫描是数据库大敌啊,查询超慢还占资源。最忌讳的就是用'%xxx%'全模糊,因为索引不生效。你可以做的是:用反转字符串加函数索引,搞个like ‘xxx%’的变形,或者用全文索引,还有就是尽量减少复杂的模糊查询,能精确查就精确查,不行就给它装个专业搜索引擎。放心,这样数据库稳得飞起来,啥压力都没啦!







新增评论